Manually specifying FFTs
Hansjörg Neth and Nathaniel Phillips
2026-05-03
Source:vignettes/FFTrees_mytree.Rmd
FFTrees_mytree.RmdManually specifying FFTs
We usually create fast-and-frugal trees (FFTs) from data by using the
FFTrees() function (see the Main
guide: FFTrees overview and the vignette on Creating FFTs with FFTrees() for
instructions). However, we occasionally may want to design and evaluate
specific FFTs (e.g., to test a hypothesis or include or exclude some
variables based on theoretical considerations).
There are two ways to manually define fast-and-frugal trees with the
FFTrees() function:
as a sentence using the
my.treeargument (the easier way), oras a data frame using the
tree.definitionsargument (the harder way).
Both of these methods require some data to evaluate the performance of FFTs, but will bypass the tree construction algorithms built into the FFTrees package. As manually created FFTs are not optimized for specific data, the key difference between fitting and predicting disappears for such FFTs. Although we can still use two sets of ‘train’ vs. ‘test’ data, a manually defined FFT is not fitted and hence should not be expected to perform systematically better on ‘train’ data than on ‘test’ data.
1. Using my.tree
The first method for manually defining an FFT is to use the
my.tree argument, where my.tree is a sentence
describing a (single) FFT. When this argument is specified in
FFTrees(), the function — or rather its auxiliary
fftrees_wordstofftrees() function — attempts to interpret
the verbal description and convert it into a valid definition of an FFT
(as part of an FFTrees object).
For example, let’s use the heartdisease data to find out
how some predictor variables (e.g., sex, age,
etc.) predict the criterion variable (diagnosis):
| sex | age | thal | cp | ca | diagnosis |
|---|---|---|---|---|---|
| 1 | 63 | fd | ta | 0 | FALSE |
| 1 | 67 | normal | a | 3 | TRUE |
| 1 | 67 | rd | a | 2 | TRUE |
| 1 | 37 | normal | np | 0 | FALSE |
| 0 | 41 | normal | aa | 0 | FALSE |
| 1 | 56 | normal | aa | 0 | FALSE |
Here’s how we could verbally describe an FFT by using the first three cues in conditional sentences:
in_words <- "If sex = 1, predict True.
If age < 45, predict False.
If thal = {fd, normal}, predict True.
Otherwise, predict False."As we will see shortly, the FFTrees() function accepts
such descriptions (assigned here to a character string
in_words) as its my.tree argument, creates a
corresponding FFT, and evaluates it on a corresponding dataset.
Verbally defining FFTs
Here are some instructions for manually specifying trees:
Each node must start with the word “If” and should correspond to the form:
If <CUE> <DIRECTION> <THRESHOLD>, predict <EXIT>.Numeric thresholds should be specified directly (without brackets), like
age > 21.For categorical variables, factor thresholds must be specified within curly braces, like
sex = {male}. For factors with sets of values, categories within a threshold should be separated by commas likeeyecolor = {blue,brown}.To specify cue directions, standard logical comparisons
=,!=,<,>=(etc.) are valid. For numeric cues, only use>,>=,<, or<=. For factors, only use=or!=.Positive exits are indicated by
True, while negative exits are specified byFalse.The final node of an FFT is always bi-directional (i.e., has both a positive and a negative exit). The description of the final node always mentions its positive (
True) exit first. The textOtherwise, predict EXITthat we have included in the example above is actually not necessary (and ignored).
Example
Now, let’s use our verbal description of an FFT (assigned to
in_words above) as the my.tree argument of the
FFTrees() function. This creates a corresponding FFT and
applies it to the heartdisease data:
# Create FFTrees from a verbal FFT description (as my.tree):
my_fft <- FFTrees(formula = diagnosis ~.,
data = heartdisease,
main = "My 1st FFT",
my.tree = in_words)Running FFTrees() with the my.tree argument
creates an object my_fft that contains one FFT. A verbal
description of this tree can be printed by inwords(my_fft),
but we want to print or plot the object to evaluate the tree’s
performance on training or testing data. Let’s see how well our manually
constructed FFT (my_fft) did on the training data:
# Inspect FFTrees object:
plot(my_fft, data = "train")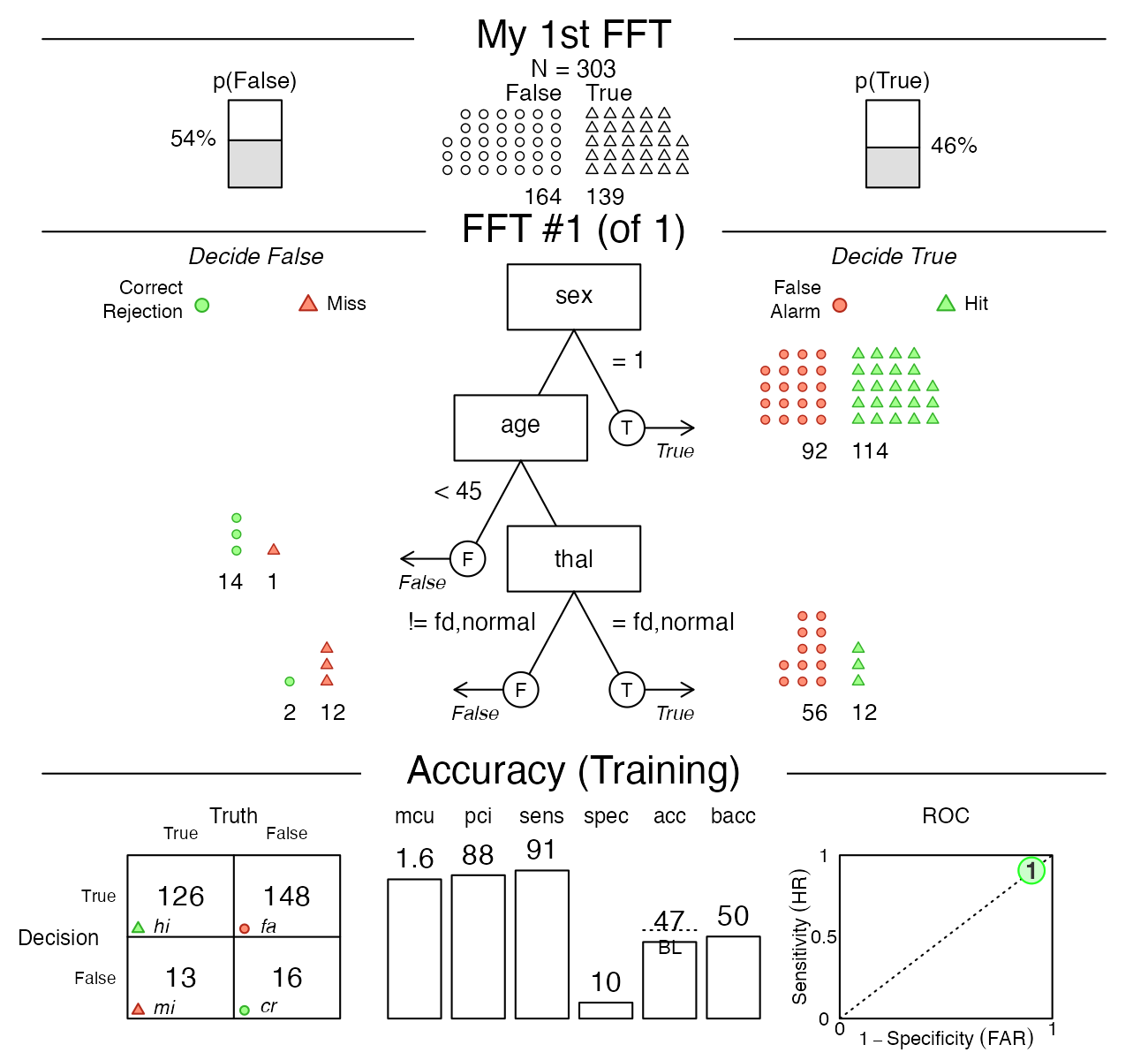
Figure 1: An FFT manually constructed using the
my.tree argument of FFTrees().
When manually constructing a tree, the resulting FFTrees
object only contains a single FFT. Hence, the ROC plot (in the right
bottom panel of Figure 1) cannot show a range of FFTs,
but locates the constructed FFT in ROC space.
The formal definition of our new FFT is available from the
FFTrees object my_fft:
# Get FFT definition(s):
get_fft_df(my_fft) # my_fft$trees$definitions#> # A tibble: 1 × 7
#> tree nodes classes cues directions thresholds exits
#> <int> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1 3 n;n;c sex;age;thal =;>=;= 1;45;fd,normal 1;0;0.5Note that the 2nd node in this FFT (using the age cue)
is predicting the noise outcome (i.e., a non-final exit value
of 0 or FALSE, shown to the left). As our tree
definitions always refer to the signal outcome (i.e., a
non-final exit value of 1 or TRUE, shown to
the right), the direction symbol of a left exit (i.e., the 2nd node in
Figure 1: if age < 45,
predict 0 or noise) must be flipped relative to its
appearance in the tree definition (if age >= 45,
predict 1 or signal). Thus, the plot and the formal
definition describe the same FFT.
As it turns out, the performance of our first FFT created from a verbal description is a mixed affair: The tree has a rather high sensitivity (of 91%), but its low specificity (of only 10%) allows for many false alarms. Consequently, its accuracy measures fail to exceed the baseline level.
Creating an alternative FFT
Let’s see if we can come up with a better FFT. The following example
uses the cues thal, cp, and ca in
the my.tree argument:
# Create a 2nd FFT from an alternative FFT description (as my.tree):
my_fft_2 <- FFTrees(formula = diagnosis ~.,
data = heartdisease,
main = "My 2nd FFT",
my.tree = "If thal = {rd,fd}, predict True.
If cp != {a}, predict False.
If ca > 1, predict True.
Otherwise, predict False.")As FFTrees aims to interpret the
my.tree argument to the best of its abilities, there is
some flexibility in entering a verbal description of an FFT. For
instance, we also could have described our desired FFT in more flowery
terms:
# Create a 2nd FFT from an alternative FFT description (as my.tree):
my_fft_2 <- FFTrees(formula = diagnosis ~.,
data = heartdisease,
main = "My 2nd FFT",
my.tree = "If thal equals {rd,fd}, we shall say True.
When Cp differs from {a}, let's predict False.
Whenever CA happens to exceed 1, we will insist on True.
Else, we give up and go away.") However, as the vocabulary of FFTrees is limited, it
is safer to enter cue directions in their symbolic form (i.e.,
using =, <, <=,
>, >=, or !=).1 To verify
that FFTrees interpreted our my.tree
description as intended, let’s check whether the FFT of
inwords(my_fft_2) yields a description that corresponds to
what we wanted:
inwords(my_fft_2)#> [1] "If thal = {rd,fd}, decide True."
#> [2] "If cp != {a}, decide False."
#> [3] "If ca > 1, decide True, otherwise, decide False."As this seems (a more prosaic version of) what we wanted, let’s visualize this tree (to evaluate its performance) and briefly inspect its tree definition:
# Visualize FFT:
plot(my_fft_2)
# FFT definition:
get_fft_df(my_fft_2) # my_fft_2$trees$definitions
#> # A tibble: 1 × 7
#> tree nodes classes cues directions thresholds exits
#> <int> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1 3 c;c;n thal;cp;ca =;=;> rd,fd;a;1 1;0;0.5
# Note the flipped direction value for 2nd cue (exit = '0'):
# 'if (cp = a), predict 1' in the tree definition corresponds to
# 'if (cp != a), predict 0' in the my.tree description and plot. 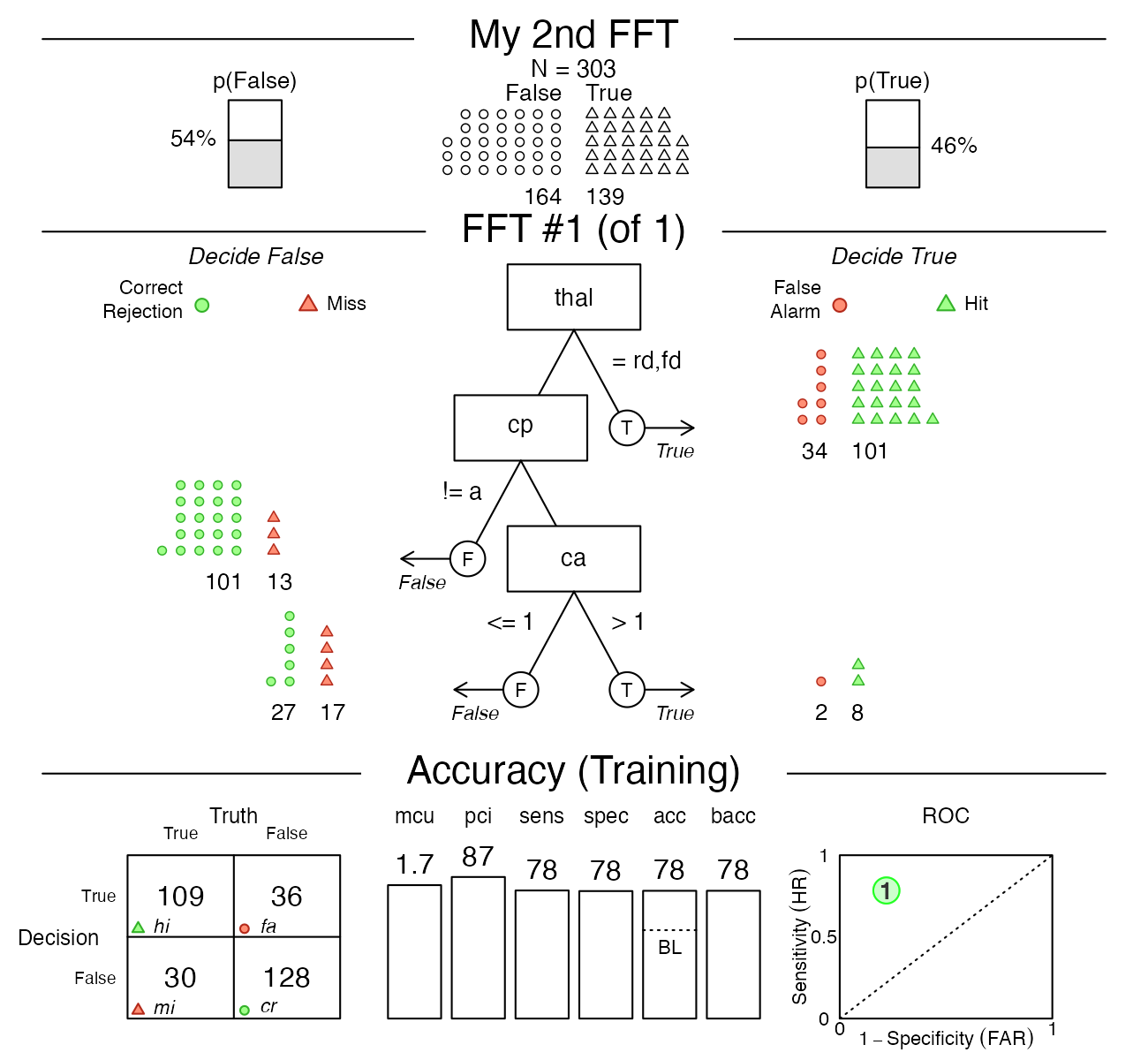
Figure 2: Another FFT manually constructed using the
my.tree argument of FFTrees().
This alternative FFT is nicely balancing sensitivity and specificity and performs much better overall. Nevertheless, it is still far from perfect — so check out whether you can create even better ones!
2. Using tree.definitions
More experienced users may want to define and evaluate more than one
FFT at a time. To achieve this, the FFTrees() function
allows providing sets of tree.definitions (as a data
frame). However, as questions regarding specific trees usually arise
later in the exploration of FFTs, the tree.definitions
argument is mostly used in combination with an existing
FFTrees object x. In this case, most
parameters (e.g., regarding the formula, data
and various goals) from the FFTrees object x
are being kept, but the object is re-evaluated for a new set of
tree.definitions.
As FFTs are simple and transparent rules for solving binary
classification problems, it would be neat to directly manipulate and
evaluate these rules. For this purpose, FFTrees
provides a set of tree manipulation functions (see
Figure 3 below). Some of these functions extract sets
of existing FFT definitions (from x) and convert individual
FFT definitions into a more manageable (“tidy”) format. Other functions
allow to edit and trim these FFT definitions (e.g., by adding, changing,
reordering or removing nodes). Finally, further functions allow to
re-convert individual FFT definitions into sets of definitions, and to
collect and re-evaluate them on data.
The basic workflow to get, change, and use FFT definitions contains five steps:
- Get (sets of) FFT definitions
- Select and convert an individual FFT into a tidy data format
- Manipulate the FFT (e.g., by changing its nodes or exits)
- Re-convert the changed definition into the original data format
- Collect sets of changed FFT definitions and/or evaluate them on data
Conceptually, this workflow boils down to first creating an FFT model for some data, then manipulating the model, and finally re-evaluating it on the data. The tools involved in this workflow allow editing the grammar of FFTs.
Overview: Retrieving, manipulating, and using FFT definitions
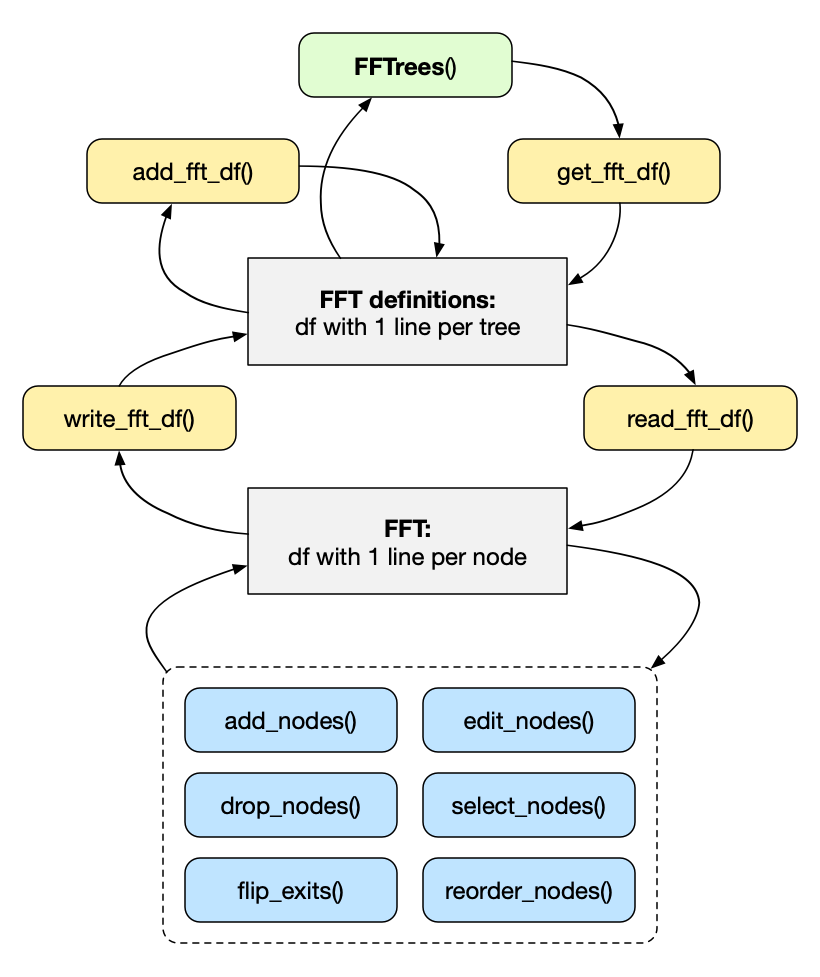
Figure 3: Overview of 4 tree definition and conversion
functions (in yellow)
and 6 tree trimming functions (in blue).
Figure 3 provides an overview of the functions provided for converting and manipulating FFT definitions. We can distinguish between three cycles:
-
Cycle 1: Obtaining and collecting sets of FFT
definitions. The main
FFTrees()function creates anFFTreesobjectxwith and from corresponding tree definitions. The following functions get, collect, and evaluate FFT definitions:-
get_fft_df()extracts the set of current FFT definitions (fromx$trees$definitions).
-
add_fft_df()adds one or more FFT definitions to an existing set of FFT definitions. Thus, the function allows collecting sets of FFT definitions.
- the
tree.definitionsargument of the mainFFTrees()function allows evaluating sets of FFT definitions for some data.
-
-
Cycle 2: Converting between two tree definition
formats (both stored as data frames):
-
read_fft_df()selects a single FFT from a set of FFT definitions and converts it into a tidy data format (as a data frame in which each row represents a node). -
write_fft_df()converts a single FFT from the tidy data frame (with 1-row-per-node) into the 1-row-per FFT format used byadd_fft_df()and thetree.definitionsargument ofFFTrees().
-
-
Cycle 3: Manipulating an individual tree definition
by a set of tree editing and trimming functions:
-
add_nodes()allows adding new nodes to an FFT; -
drop_nodes()allows deleting nodes of an FFT; -
edit_nodes()allows changing existing nodes of an FFT; -
flip_exits()allows changing the exit direction of existing nodes; -
reorder_nodes()allows changing the order of FFT nodes; -
select_nodes()allows filtering existing nodes of an FFT.
-
The following example illustrates the interplay of these functions in a typical workflow. When looking at Figure 3, we first move down on the right side (from retrieving sets of FFT definitions to manipulating individual FFTs) and then move up on the left side (to re-convert individual FFTs into sets of FFT definitions).
Example
We illustrate a typical workflow by redefining some FFTs that were
built in the Tutorial: FFTs for heart
disease and evaluating them on the (full) heartdisease
data.
To obtain a set of existing tree definitions, we use our default
algorithm to create an FFTrees object x:
# Create an FFTrees object x:
x <- FFTrees(formula = diagnosis ~ ., # criterion and (all) predictors
data = heart.train, # training data
data.test = heart.test, # testing data
main = "Heart Disease 1", # initial label
decision.labels = c("low risk", "high risk"), # exit labels
quiet = TRUE) # hide user feedbackAs we have seen in the Tutorial,
evaluating this expression yields a set of 7 FFTs. Rather than
evaluating them individually (e.g., by using print(x) or
plot(x) commands to inspect specific trees), we now extract
the tree definitions to select and modify individual FFTs. As the
definitions are stored as part of the FFTrees
object x, this could be achieved by evaluating
x$trees$definitions or by
summary(x)$definitions. Alternatively, we can use the
get_fft_df() utility function on x to obtain
the set of generated tree definitions:
# Get tree definitions of x:
(tree_dfs <- get_fft_df(x))#> # A tibble: 7 × 7
#> tree nodes classes cues directions thresholds exits
#> <int> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1 3 c;c;n thal;cp;ca =;=;> rd,fd;a;0 1;0;0.5
#> 2 2 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 1;0;1;0.5
#> 3 3 3 c;c;n thal;cp;ca =;=;> rd,fd;a;0 0;1;0.5
#> 4 4 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 1;1;0;0.5
#> 5 5 3 c;c;n thal;cp;ca =;=;> rd,fd;a;0 0;0;0.5
#> 6 6 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 0;0;0;0.5
#> 7 7 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 1;1;1;0.5The resulting R object tree_dfs is a data frame with
7 variables. Each of its 7 rows defines an FFT in the context of our
current FFTrees object x (see the vignette on
Creating FFTs with FFTrees() for
help on interpreting tree definitions). As the “ifan” algorithm
responsible for creating these trees yields a family of highly similar
FFTs (which vary only by their exits, and may truncate some cues), we
may want to explore alternative versions of these trees.
All 7 FFTs defined in tree_dfs share the three cues
thal, cp, and ca, in this order.
Let’s assume we had reasons to explore the cue order thal,
ca, and cp.
Obtaining individual tree definitions
Before we can apply our tree editing functions, we first select an
initial FFT that we want to manipulate further. This is the job of
read_fft_df() (see Cycle 2 of
Figure 3):
-
read_fft_df()selects an FFT definition and converts it into a tidy data frame.
In our present case, we select and convert tree 1:
(fft_1 <- read_fft_df(ffts_df = tree_dfs, tree = 1))#> class cue direction threshold exit
#> 1 c thal = rd,fd 1
#> 2 c cp = a 0
#> 3 n ca > 0 0.5The resulting R object fft_1 selected the definition of
tree 1 and converted it into a tidy data frame. Each of its 3 rows
defines a node of this FFT. This format can be understood and
manipulated more easily than the more compact format used in row 1 of
tree_dfs (but both formats can be converted into each other
by the complementary functions read_fft_df() and
write_fft_df()).
Manipulating individual tree definitions
Having selected one FFT and converted it into a tidy data
frame fft_1, we can use various tree trimming functions to
edit or manipulate the definition of an individual tree (see
Cycle 3 of Figure 3).
Reordering nodes
In our example, our selected FFT uses the cues thal,
cp, and ca, but we wanted to explore the
alternative cue order thal, ca,
and cp. In other words, we need to swap the order of the
2nd and 3rd cues of fft_1. This is the purpose of the
reorder_nodes() function:
-
reorder_nodes()allows changing the order of FFT nodes.
In contrast to the read_fft_df() function above, the
tree editing functions of Cycle 3 all require an
individual FFT-definition (as a tidy data frame) as their first
argument fft. In the case of reorder_nodes(),
the second argument order specifies a numeric vector for
the desired node positions (i.e., the integers from 1 to
nrow(fft) in any order). Thus, swapping the order of the
2nd and 3rd nodes of fft_1 is achieved as follows:
(my_fft_1 <- reorder_nodes(fft = fft_1, order = c(1, 3, 2)))#> reorder_nodes: Former exit node now is node 2
#> #> class cue direction threshold exit
#> 1 c thal = rd,fd 1
#> 2 n ca > 0 1
#> 3 c cp = a 0.5Swapping the final two nodes implies that the final node of
fft_1 (using the numerical cue ca) becomes a
non-final cue, whereas the previous middle node (using a categorical
cue cp) becomes a final cue (see the corresponding feedback
message). By default, the previous exit cue becomes a signal exit (here:
exit 1, i.e., predicting a TRUE value for the diagnosis
criterion). Saving the resulting tree definition (stored in the same
tidy data frame format as fft_1) as an R object
my_fft_1 will allow us to collect our modified FFTs
later.
Flipping exits As we had no specific exit structure
in mind when deciding to explore the cue order thal,
ca, and cp, we will explore all possible exit
directions. As every non-final node allows for two alternative exits, a
tree containing
nodes
has
exit
structures (i.e.,
for 3 cues). The
exit
structures in addition to my_fft_1 can be obtained by
flipping the exit directions of the first, second, or both non-final
nodes. Each alternative can be achieved by applying the
flip_exits() function to my_fft_1:
-
flip_exits()allows changing the exit direction of existing nodes.
For instance, the tree definition with a signal exit at the first
node of my_fft_1 can be reversed into a non-signal node as
follows:
(my_fft_2 <- flip_exits(my_fft_1, nodes = 1))#> class cue direction threshold exit
#> 1 c thal = rd,fd 0
#> 2 n ca > 0 1
#> 3 c cp = a 0.5Using magrittr pipes to combine steps
The tree conversion and editing functions do not need to be used
separately. As their first argument represents the data object to be
manipulated, they can be viewed as verbs in a tree manipulation language
and chained into longer command sequences by using the
magrittr pipe operator. For instance, reversing the
exit of the 2nd cue of my_fft_1 could be achieved as
follows:
library(magrittr)
(my_fft_3 <- my_fft_1 %>%
flip_exits(nodes = 2))#> class cue direction threshold exit
#> 1 c thal = rd,fd 1
#> 2 n ca > 0 0
#> 3 c cp = a 0.5Similarly, the five steps from FFTrees
object x to the tree definition with the alternative exit
structure of my_fft_4 could be chained into a single pipe
as follows:
(my_fft_4 <- x %>%
get_fft_df() %>%
read_fft_df(tree = 1) %>%
reorder_nodes(order = c(1, 3, 2)) %>%
flip_exits(nodes = c(1, 2)))#> reorder_nodes: Former exit node now is node 2
#> #> class cue direction threshold exit
#> 1 c thal = rd,fd 0
#> 2 n ca > 0 0
#> 3 c cp = a 0.5To evaluate our four alternative tree definitions, we need to
re-convert them into the 1-line-per-FFT format (using
write_fft_df()) and gather them in a single data frame
(using add_fft_df()). In Figure 3, this
corresponds to moving upwards on the left (from individual FFT
definitions in a tidy data frame to combining sets of FFT definitions in
a single data frame).
Re-converting and collecting sets of tree definitions
Having created four modified tree definitions (i.e.,
my_fft_1 to my_fft_4), we now want to
re-convert them from the tidy data frame (with each row representing an
FFT node) to the (non-tidy) data frame format (in which each row
represents and entire FFT). The more compact format allows us to gather
several FFT definitions in one data frame, so that we can evaluate them
together for some data in a call to the main FFTrees()
function. In Figure 3, the corresponding steps are
shown on the left sides of Cycle 2 and
Cycle 1.
To re-convert between the two tree definition formats (both stored as
data frames), we use the write_fft_df() function:
-
write_fft_df()converts a single FFT from the tidy data frame (with 1-row-per-node) into the 1-row-per FFT format used byadd_fft_df()and thetree.definitionsargument ofFFTrees().
In addition to the FFT definition to convert (e.g.,
my_fft_1), the tree argument allows providing
a numeric ID which will later allow us to identify the FFT within a
set:
(my_tree_dfs <- write_fft_df(my_fft_1, tree = 1))#> tree nodes classes cues directions thresholds exits
#> 1 1 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 1;1;0.5This creates an R object my_tree_dfs as a (non-tidy)
data frame in which the definition of my_fft_1 occupies
only one row.
Next, we add the other FFT definitions to the
my_tree_dfs data frame. This can be achieved by the
add_fft_df() function:
-
add_fft_df()adds one or more FFT definitions to an existing set of FFT definitions. Thus, the function allows collecting sets of FFT definitions.
However, as this first requires converting each of the tidy FFT
definitions into the more compact 1-row-per FFT format, we use a series
of command pipes. Each pipe starts from a tidy FFT definition and
applies write_fft_df() (with an ID) and
add_fft_df (to my_tree_dfs), before
re-assigning the modified data frame as my_tree_dfs
again:
my_tree_dfs <- my_fft_2 %>%
write_fft_df(tree = 2) %>%
add_fft_df(my_tree_dfs)
my_tree_dfs <- my_fft_3 %>%
write_fft_df(tree = 3) %>%
add_fft_df(my_tree_dfs)
my_tree_dfs <- my_fft_4 %>%
write_fft_df(tree = 4) %>%
add_fft_df(my_tree_dfs)
my_tree_dfs#> tree nodes classes cues directions thresholds exits
#> 1 1 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 1;1;0.5
#> 2 2 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 0;1;0.5
#> 3 3 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 1;0;0.5
#> 4 4 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 0;0;0.5The resulting data frame my_tree_dfs contains 4 FFT
definitions in its 4 rows. Per our design (above), they only differ in
the values of their tree ID and the structures of their
exits.
Applying sets of tree definitions to data
Having edited and collected a set of tree definitions, we now can
evaluate the corresponding FFTs on some data. We can do this by
providing our set of tree definitions (stored in the
my_tree_dfs data frame) to the
tree.definitions argument of the main
FFTrees() function:
- The
tree.definitionsargument of the mainFFTrees()function allows evaluating sets of FFT definitions for some data.
When using the main FFTrees() function with a set of
tree.definitions (as a data frame in which each line
contains the definition of one FFT), we can provide an existing
FFTrees object (e.g., x from above).
Importantly, however, the input of tree.definitions
prevents the generation of new FFTs (via the “ifan” or “dfan”
algorithms) and instead evaluates the FFT definitions provided on the
data specified:2
# Evaluate new tree.definitions for an existing FFTrees object x:
y <- FFTrees(object = x, # existing FFTrees object x
tree.definitions = my_tree_dfs, # new set of FFT definitions
main = "Heart Disease 2" # new label
)As we can see from the feedback messages, providing an
FFTrees object (here x) re-uses its datasets,
parameters, and labels, unless they are overwritten by new values. The
resulting FFTrees object y contains the
summary statistics resulting from applying the 4 FFT definitions of
my_tree_dfs to the datasets that were used to create
x (i.e., data = heart.train and
data.test = heart.test).
We now can assess and visualize the performance of the FFTs in the
usual ways, e.g., by the summary(), print()
and plot() functions for y or its trees:
summary(y)#> Heart Disease 2
#>
#> FFTrees
#> - Trees: 4 fast-and-frugal trees predicting diagnosis
#> - Parameters: algorithm = 'ifan', max.levels = 4,
#> stopping.rule = 'exemplars', stopping.par = 0.1,
#> goal = 'bacc', goal.chase = 'bacc', goal.threshold = 'bacc'.
#>
#>
#> Table: Tree definitions.
#>
#> | tree| nodes|classes |cues |directions |thresholds |exits |
#> |----:|-----:|:-------|:----------|:----------|:----------|:-------|
#> | 1| 3|c;n;c |thal;ca;cp |=;>;= |rd,fd;0;a |1;0;0.5 |
#> | 2| 3|c;n;c |thal;ca;cp |=;>;= |rd,fd;0;a |0;1;0.5 |
#> | 3| 3|c;n;c |thal;ca;cp |=;>;= |rd,fd;0;a |1;1;0.5 |
#> | 4| 3|c;n;c |thal;ca;cp |=;>;= |rd,fd;0;a |0;0;0.5 |
#>
#>
#> Table: Tree statistics on training data [p(True) = 44%].
#>
#> | tree| n| hi| fa| mi| cr| sens| spec| far| ppv| npv| dprime| acc| bacc| wacc| cost_dec| cost_cue| cost| pci| mcu|
#> |----:|---:|--:|--:|--:|--:|----:|----:|----:|----:|----:|------:|----:|----:|----:|--------:|--------:|----:|----:|----:|
#> | 1| 150| 54| 18| 12| 66| 0.82| 0.79| 0.21| 0.75| 0.85| 1.69| 0.80| 0.80| 0.80| 0.20| 1.76| 1.96| 0.86| 1.76|
#> | 2| 150| 44| 7| 22| 77| 0.67| 0.92| 0.08| 0.86| 0.78| 1.79| 0.81| 0.79| 0.79| 0.19| 1.58| 1.77| 0.88| 1.58|
#> | 3| 150| 63| 42| 3| 42| 0.95| 0.50| 0.50| 0.60| 0.93| 1.66| 0.70| 0.73| 0.73| 0.30| 1.98| 2.28| 0.85| 1.98|
#> | 4| 150| 28| 2| 38| 82| 0.42| 0.98| 0.02| 0.93| 0.68| 1.74| 0.73| 0.70| 0.70| 0.27| 1.68| 1.95| 0.87| 1.68|
#>
#>
#> Table: Tree statistics on test data [p(True) = 48%].
#>
#> | tree| n| hi| fa| mi| cr| sens| spec| far| ppv| npv| dprime| acc| bacc| wacc| cost_dec| cost_cue| cost| pci| mcu|
#> |----:|---:|--:|--:|--:|--:|----:|----:|----:|----:|----:|------:|----:|----:|----:|--------:|--------:|----:|----:|----:|
#> | 1| 153| 64| 19| 9| 61| 0.88| 0.76| 0.24| 0.77| 0.87| 1.86| 0.82| 0.82| 0.82| 0.18| 1.69| 1.87| 0.87| 1.69|
#> | 2| 153| 49| 8| 24| 72| 0.67| 0.90| 0.10| 0.86| 0.75| 1.71| 0.79| 0.79| 0.79| 0.21| 1.70| 1.91| 0.87| 1.70|
#> | 3| 153| 70| 45| 3| 35| 0.96| 0.44| 0.56| 0.61| 0.92| 1.55| 0.69| 0.70| 0.70| 0.31| 1.90| 2.22| 0.85| 1.90|
#> | 4| 153| 28| 0| 45| 80| 0.38| 1.00| 0.00| 1.00| 0.64| 2.44| 0.71| 0.69| 0.69| 0.29| 1.71| 2.01| 0.87| 1.71|
# Visualize individual FFTs:
# plot(y, tree = 1)Comparing the accuracy statistics of our new FFTs (in
object y) to our original FFTs (in object x)
shows that swapping the 2nd and 3rd cues hardly had an effect. Upon
reflection, this is not surprising: Most people are still classified
into the same categories as before. However, if we were to evaluate the
costs of classification (e.g., by considering the pci
and mcu measures or the cost measures for cue
usage), we could still detect differences between FFTs that show the
same accuracy.
Details
We just created a new FFTrees object y by
using FFTrees object x for a set of customized
FFTs defined by the tree.definitions argument. This
circumvented the FFT building algorithms and used the provided FFT
definitions instead. Thus, the ordinary distinction between training and
test data no longer applies in this context: As no model is being fitted
here, both sets were used to evaluate (or “test”) the FFTs in
tree.definitions on these data.
Acknowledging this, we may use the full dataset of
heartdisease, rather than splitting it into two distinct
subsets:
# Create a new FFTrees object z:
z <- FFTrees(formula = diagnosis ~ .,
data = heartdisease, # using full dataset
tree.definitions = my_tree_dfs, # new set of FFT definitions
main = "Heart Disease 3" # new label
)As before, we can evaluate the performance of our FFTs by obtaining a
summary, or printing or plotting individual FFTs from the
FFTrees object z:
Finally, if we mostly care about comparing our new FFTs with the
automatically created ones, we could have added our new set
my_tree_dfs to the old set (tree_dfs, obtained
from x above).
(all_fft_dfs <- add_fft_df(my_tree_dfs, tree_dfs))#> # A tibble: 11 × 7
#> tree nodes classes cues directions thresholds exits
#> <int> <int> <chr> <chr> <chr> <chr> <chr>
#> 1 1 3 c;c;n thal;cp;ca =;=;> rd,fd;a;0 1;0;0.5
#> 2 2 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 1;0;1;0.5
#> 3 3 3 c;c;n thal;cp;ca =;=;> rd,fd;a;0 0;1;0.5
#> 4 4 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 1;1;0;0.5
#> 5 5 3 c;c;n thal;cp;ca =;=;> rd,fd;a;0 0;0;0.5
#> 6 6 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 0;0;0;0.5
#> 7 7 4 c;c;n;c thal;cp;ca;slope =;=;>;= rd,fd;a;0;flat,down 1;1;1;0.5
#> 8 8 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 1;1;0.5
#> 9 9 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 0;1;0.5
#> 10 10 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 1;0;0.5
#> 11 11 3 c;n;c thal;ca;cp =;>;= rd,fd;0;a 0;0;0.5Doing so (e.g., by using the add_fft_df() function)
creates a superset of 11 tree definitions, which can be evaluated
together on the heartdisease data:
# Create a new FFTrees object a:
all <- FFTrees(formula = diagnosis ~ .,
data = heartdisease, # using full dataset
tree.definitions = all_fft_dfs, # new set of FFT definitions
main = "Heart Disease 4", # new label
)
# Summarize results:
summary(all)Evaluating the performance of the corresponding FFTs (e.g., by
summary(all)) shows that reversing the final two cues had
little to no effects on accuracy (but note minor differences in costs,
e.g., mcu).3
Vignettes
Here is a complete list of the vignettes available in the FFTrees package:
| Vignette | Description | |
|---|---|---|
| Main guide: FFTrees overview | An overview of the FFTrees package | |
| 1 | Tutorial: FFTs for heart disease | An example of using FFTrees() to model
heart disease diagnosis |
| 2 | Accuracy statistics | Definitions of accuracy statistics used throughout the package |
| 3 | Creating FFTs with FFTrees() | Details on the main FFTrees()
function |
| 4 | Manually specifying FFTs | How to directly create FFTs without using the built-in algorithms |
| 5 | Visualizing FFTs | Plotting FFTrees objects, from full trees
to icon arrays |
| 6 | Examples of FFTs | Examples of FFTs from different datasets contained in the package |