Overview: Creating FFTs with FFTrees
Nathaniel D. Phillips and Hansjörg Neth
2026-05-03
Source:vignettes/guide.Rmd
guide.RmdThe R package FFTrees (Phillips et al., 2017, 2023) makes it easy to create, visualize, and evaluate fast-and-frugal decision trees (FFTs). FFTs are simple and transparent decision algorithms for solving binary classification problems in an effective and efficient fashion.
Fast-and-frugal trees (FFTs)
A fast-and-frugal tree (FFT) (Martignon et al., 2003) is a set of
hierarchical rules for solving binary classification tasks based on very
little pieces of information (usually using 4 or fewer cues). In
contrast to more complex decision trees, each node of an FFT has exactly
two branches. A branch can either contain another cue (i.e., ask another
question) or lead to an exit (i.e., yield a decision or prediction
outcome).
Each non-final node of an FFT has one exit branch and the final node has
two exit branches.
FFTs are simple and effective decision strategies that use minimal information for making decisions in binary classification problems (see Gigerenzer & Todd, 1999; Gigerenzer et al., 1999). FFTs are often preferable to more complex decision strategies (such as logistic regression, LR) because they rarely over-fit data (Gigerenzer & Brighton, 2009) and are easy to interpret, implement, and communicate in real-world settings (Marewski & Gigerenzer, 2012). FFTs have been designed to tackle many real world tasks from making fast decisions in emergency rooms (Green & Mehr, 1997) to detecting depression (Jenny et al., 2013).
Whereas their performance and success are empirical questions, a key theoretical advantage of FFTs is their transparency to decision makers and anyone aiming to understand and evaluate the details of an algorithm. In the words of Burton et al. (2020), “human users could interpret, justify, control, and interact with a fast-and-frugal decision aid” (p. 229).
Using the FFTrees package
The FFTrees package makes it easy to produce,
display, and evaluate FFTs (Phillips et al.,
2017). The package’s main function is FFTrees()
which takes formula formula and dataset data
arguments and returns several FFTs that attempt to classify training
cases into criterion classes. The FFTs created can then be used to
predict new data to cross-validate their performance.
Here is an example of using the main FFTrees() function
to fit FFTs to heart.train data:
# Create a fast-and-frugal tree (FFT) predicting heart disease:
heart.fft <- FFTrees(formula = diagnosis ~.,
data = heart.train,
data.test = heart.test,
main = "Heart Disease",
decision.labels = c("Healthy", "Diseased"))The resulting FFTrees object heart.fft
contains 7 FFTs that were fitted to the heart.test data. To
evaluate a tree’s predictive performance, we compare its predictions for
the un-trained heart.test data with their true criterion
values. Here is how we can apply the best training FFT to the
heart.test data:
# Visualize predictive performance:
plot(heart.fft, data = "test")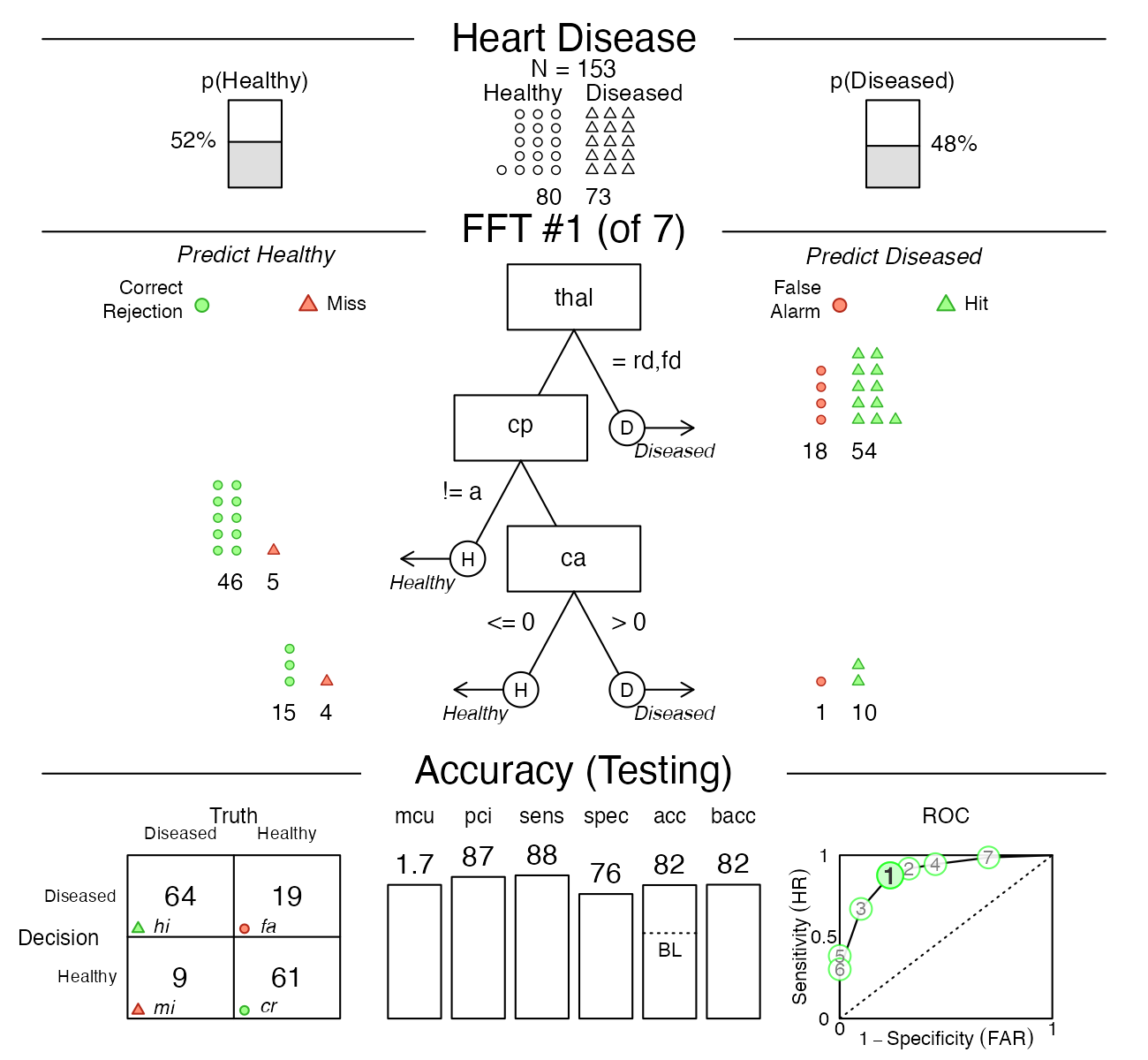
A fast-and-frugal tree (FFT) to predict heart disease status.
Getting started
To start using the FFTrees package, we recommend studying the Tutorial: Creating FFTs for heart disease. The tutorial illustrates the basics steps of creating, visualizing, and evaluating fast-and-frugal trees (FFTs). The scientific background of FFTs and the development of FFTrees are described in Phillips et al. (2017) (doi 10.1017/S1930297500006239 | html | PDF). The following vignettes provide details on related topics and corresponding examples.
Vignettes
Here is a complete list of the vignettes available in the FFTrees package:
| Vignette | Description | |
|---|---|---|
| Main guide: FFTrees overview | An overview of the FFTrees package | |
| 1 | Tutorial: FFTs for heart disease | An example of using FFTrees() to model
heart disease diagnosis |
| 2 | Accuracy statistics | Definitions of accuracy statistics used throughout the package |
| 3 | Creating FFTs with FFTrees() | Details on the main FFTrees()
function |
| 4 | Manually specifying FFTs | How to directly create FFTs without using the built-in algorithms |
| 5 | Visualizing FFTs | Plotting FFTrees objects, from full trees
to icon arrays |
| 6 | Examples of FFTs | Examples of FFTs from different datasets contained in the package |
Datasets
The FFTrees package contains several datasets — mostly from the UCI Machine Learning Repository — that allow you to address interesting questions when exploring FFTs:
-
blood– Which people donate blood? source -
breastcancer– Which patients suffer from breast cancer? source -
car– Which cars are acceptable? source -
contraceptive– Which factors determine whether women use contraceptives? source -
creditapproval– Which factors determine a creditcard approval? source -
fertility– Which factors predict a fertile sperm concentration? source -
forestfires– Which environmental conditions predict forest fires? source -
heartdisease– Which patients suffer from heart disease? source -
iris.v– Which iris belongs to the class “virginica”? source -
mushrooms– Which features predict poisonous mushrooms? source -
sonar– Did a sonar signal bounce off a metal cylinder (or a rock)? source -
titanic– Which passengers survived the Titanic? source -
voting– How did U.S. congressmen vote in 1984? source -
wine– What determines ratings of wine quality? source
Details about the datasets
When preparing data to be predicted by FFTs, we usually distinguish between several (categorical or numeric) predictors and a (binary) criterion variable. Table 1 provides basic information on the datasets included in the FFTrees package (see their documentation for additional details).
Table 1: Key information on the datasets included in FFTrees.
| Dataset name | Number of cases | Criterion name |
Baseline (TRUE, in %)
|
Number of predictors | Number of NAs | NAs (in %) |
|---|---|---|---|---|---|---|
| blood | 748 | donation.crit | 23.8 | 4 | 0 | 0.00 |
| breastcancer | 683 | diagnosis | 35.0 | 9 | 0 | 0.00 |
| car | 1728 | acceptability | 22.2 | 6 | 0 | 0.00 |
| contraceptive | 1473 | cont.crit | 57.3 | 9 | 0 | 0.00 |
| creditapproval | 690 | crit | 44.5 | 15 | 67 | 0.61 |
| fertility | 100 | diagnosis | 88.0 | 9 | 0 | 0.00 |
| forestfires | 517 | fire.crit | 47.0 | 12 | 0 | 0.00 |
| heartdisease | 303 | diagnosis | 45.9 | 13 | 0 | 0.00 |
| iris.v | 150 | virginica | 33.3 | 4 | 0 | 0.00 |
| mushrooms | 8124 | poisonous | 48.2 | 22 | 2480 | 1.33 |
| sonar | 208 | mine.crit | 53.4 | 60 | 0 | 0.00 |
| titanic | 2201 | survived | 32.3 | 3 | 0 | 0.00 |
| voting | 434 | party.crit | 61.5 | 16 | 391 | 5.30 |
| wine | 6497 | type | 24.6 | 12 | 0 | 0.00 |
Citing FFTrees
We had a lot of fun creating FFTrees and hope you like it too! For an accessible introduction to FFTs, we recommend reading our article in the journal Judgment and Decision Making (2017), entitled FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees (available in html | PDF ).
Citation (in APA format):
- Phillips, N. D., Neth, H., Woike, J. K. & Gaissmaier, W. (2017). FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees. Judgment and Decision Making, 12 (4), 344–368. doi 10.1017/S1930297500006239
When using FFTrees in your own work, please cite our article and spread the word, so that we can continue developing the package.
BibTeX Citation:
@article{FFTrees,
title = {FFTrees: A toolbox to create, visualize, and evaluate fast-and-frugal decision trees},
author = {Phillips, Nathaniel D and Neth, Hansjörg and Woike, Jan K and Gaissmaier, Wolfgang},
year = 2017,
journal = {Judgment and Decision Making},
volume = 12,
number = 4,
pages = {344--368},
url = {https://journal.sjdm.org/17/17217/jdm17217.pdf},
doi = {10.1017/S1930297500006239}
}Contact
The latest release of FFTrees is available at https://CRAN.R-project.org/package=FFTrees.
The latest developer version is available at https://github.com/ndphillips/FFTrees.
For comments, tips, and bug reports, please post at https://github.com/ndphillips/FFTrees/issues or contact Nathaniel at Nathaniel.D.Phillips.is@gmail.com or https://www.linkedin.com/in/nathanieldphillips/.
![]()